728x90
머신러닝 vs 딥러닝
머신러닝 : 학습 데이터를 수동으로 제공
딥러닝 : 데이터를 스스로 학습

Perceptron
인공신경망 (Artificial Neural Network, AN즘N)의 구성 요소로서
다수의 값을 입력 받아 하나의 값으로 출력하는 알고리즘.
’흐른다 = 1’ & ’안흐른다=0’ 와 같은 이진분류 (binary Classification)
모델을 학습하기 위한 지도학습(Supervised Learning) 기반 알고리즘.
Perceptron의 동작 원리

SLP (Single Layer Perceptron) - 단순 논리회로
1. SLP - AND 게이트
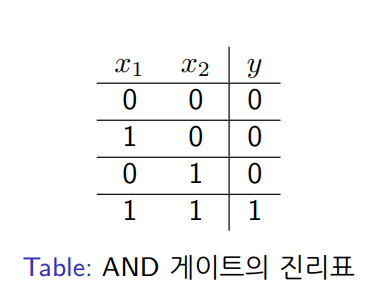
def AND(x1,x2):
w1, w2, theta =0.5, 0.5, 0.7
tmp = x1*w1 +x2*w2
if tmp <= theta: # 세타값(0.7) 보다 작거나 같으면 0을 리턴
return 0
elif tmp > theta:
return 1
2. SLP - NAND 게이트

def NAND(x1,x2):
w1, w2, theta =-0.5, -0.5, -0.7
tmp = x1*w1 +x2*w2
if tmp <= theta:
return 0
elif tmp > theta:
return 1
3. SLP - OR 게이트

def OR(x1,x2):
w1, w2, theta =0.5, 0.5, 0.2
tmp = x1*w1 +x2*w2
if tmp <= theta:
return 0
elif tmp > theta:
return 1
MLP (Multi Layer Perceptron) - 다중 논리회로

def XOR(x1, x2):
s1 = NAND(x1, x2)
s2 = OR(x1, x2)
y = AND(s1, s2)
return y
활성함수 (Activation function)


실습
1. Tensorflow로 구현하는 단순 회귀분석
import tensorflow as tf
import numpy as np
# x, y 변수 불러오기
# 리스트로
x_train =[1,2,3]
y_train =[1,2,3]
# Optimizer: 오차를 줄이는 방법. 예를 들어 경사하강법.
sgd = tf.keras.optimizers.SGD(learning_rate=0.01)
# 모델 정의하기
# model Sequential => 집
add ==> 가구넣기
compile ==> 컴퓨터 언어로 번역
model =tf.keras.models.Sequential()
# activation 활성함수
model.add(tf.keras.layers.Dense(1, input_dim=1, activation=’linear’))
# loss 손실함수
model.compile(loss="mean_squared_error",optimizer=sgd)
# 모델 훈련 및 적용
model.fit(x_train,y_train, epochs=5)
print(model.predict(np.array([5])))
=>
Epoch 1/5 1/1 [==============================] - 1s 1s/step - loss: 1.7495
Epoch 2/5 1/1 [==============================] - 0s 29ms/step - loss: 1.3844
Epoch 3/5 1/1 [==============================] - 0s 38ms/step - loss: 1.0958
Epoch 4/5 1/1 [==============================] - 0s 43ms/step - loss: 0.8676
Epoch 5/5 1/1 [==============================] - 0s 18ms/step - loss: 0.6873
2. Pytorch로 구현하는 단순 회귀분석
# x, y 변수 불러오기
# 파이토치는 텐서라는 단위로 불러온다.
x_train =torch.FloatTensor([[1], [2], [3]])
y_train =torch.FloatTensor([[1], [2], [3]])
# 가중치 (weight) 와 편차 (bias) 초기화.
requires grad를 True로 설정하면 뒤에 backward()에 대해서 미분값 (기울기)를 저장하겠다는 의미.
즉, requires_grad =True 이걸 선언해야 뒤에 w와 b 가 영향받을때마다 바뀐다.
선언하지 않으면 단지 영향받지 않는 텐서값일뿐.
W = torch.zeros(1, requires_grad =True)
b = torch.zeros(1, requires_grad =True)
# Optimizer & parameter 설정
epochs =100
optimizer =optim.SGD([W,b], lr=0.01)
# epoch 만큼 경사하강법 반복하여 모델 학습
# Pytorch는 미분을 통해 얻은 기울기로 이전에 계산된 기울기 값에 누적시키는 특징이 있어
optimizer.zero grad()를 통해 미분값을 계속 0으로 초기화 시켜줘야 함.
# .backward()는 자동미분을 실행해줌.
for epoch in range(epochs+1):
y_hat =x_train * W + b
# cost 계산
cost = torch.mean((y_hat-y_train)**2)
# cost로 y_hat 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 로그 출력
print("Epoch {} W: {:3f}, b: {:3f} Cost: {:.6f}".format(epoch, W.item(), b.item(), cost.item()))
=>
Epoch 0 W: 0.093333, b: 0.040000 Cost: 4.666667
Epoch 1 W: 0.176356, b: 0.075467 Cost: 3.692741
Epoch 2 W: 0.250210, b: 0.106903 Cost: 2.922885
Epoch 3 W: 0.315915, b: 0.134757 Cost: 2.314337
Epoch 4 W: 0.374372, b: 0.159425 Cost: 1.833292
...
# 모델 적용하기
pred_x =torch.tensor(data=[5])
pred_y =pred_x *W + b
print("predict: ", pred_y)
=>
predict: tensor([4.6533], grad_fn=<AddBackward0>)
728x90