머신러닝? 딥러닝?
머신러닝은 기계가 학습한다는 것.
예를 들어 6월, 9월 모의고사 성적으로 수능성적을 예측한다면
그 예측 수식은 아래와 같이 세울 수 있다.
수능점수 = (6월 점수 x A) + (9월 점수 x B)
위 수식에서 A 와 B는 가중치. (weight)
즉, 수능성적이라는 결과값에 얼마만큼의 중요한 가치를 차지하냐 정도로 생각하면 될 것.
(만약 9월 모의고사 결과가 수능성적에 큰 영향을 준다 생각한다면 B를 높여야 할 것이다)
머신러닝이란
실제 데이터들 (실제 학생들의 6월, 9월, 수능성적 데이터) 을
기계가 검토해서 (= 기계가 학습해서) 최적의 가중치를 찾아내는 방법.
즉, 최적의 예측모델을 만드는 것이다.
그리고 딥러닝이란
이러한 머신러닝의 한가지 방법론으로서
뉴럴 네트워크를 이용한 머신러닝이다.
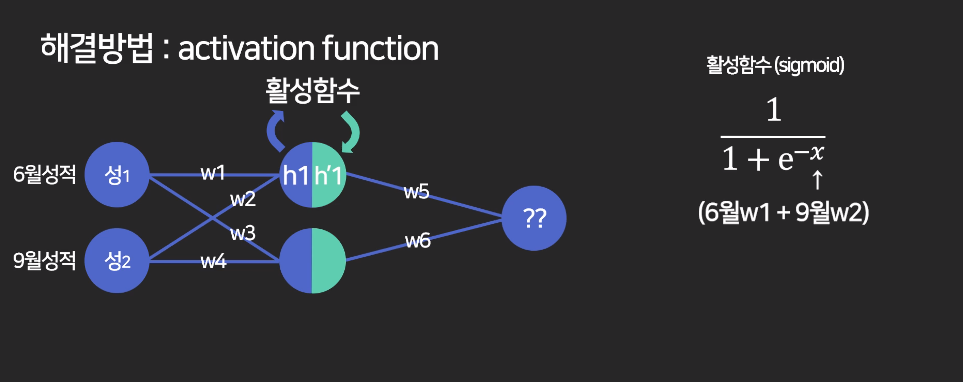
활성함수(activation function)
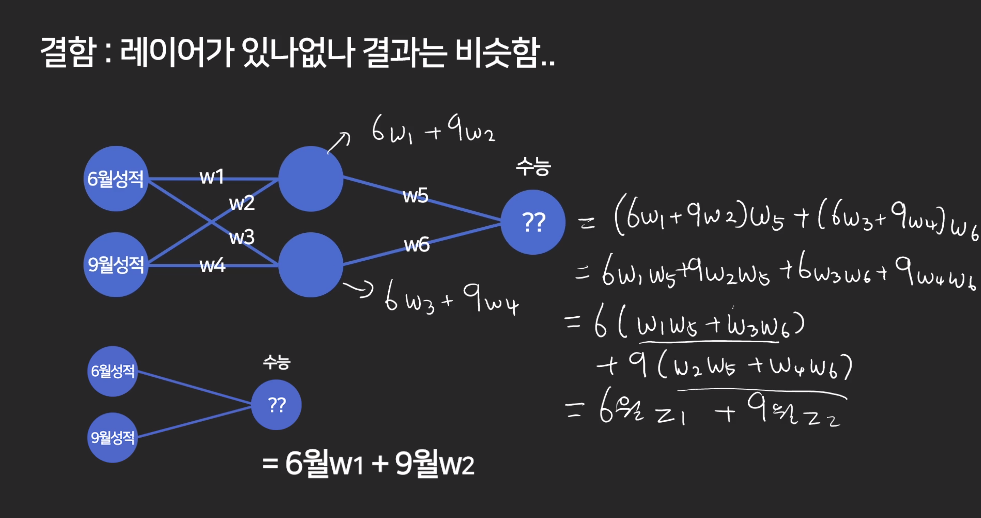
중간에 히든레이어를 넣어도 결국 예측 결과는 같다.
즉,
레이어 없는 결과 (6월w1 + 9월w2) 와
레이어 있는 결과 (6월(w1w5 + w3w6) + 9월(w2w5+w4w6)) 가 같다.
이 문제를 해결하기 위해 중간 레이어에 활성함수를 도입함.
만약 시그모이드 함수라면 0~1 사이로 값을 짜부라뜨림.
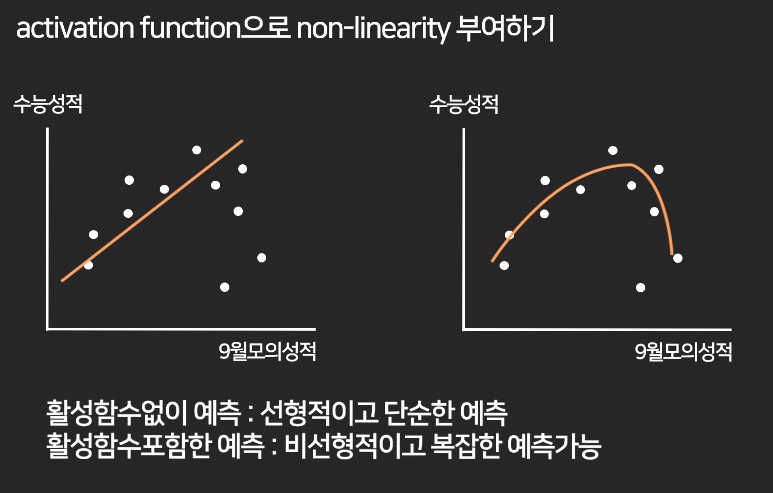
이렇게 활성함수를 통해 레이어에 의미를 주면
비선형적인 예측도 가능해진다.
손실함수 (loss function)
위 수능성적 예측모델로 예측한 수능성적과
실제 수능성적의 값을 빼면 오차가 나오겠지.
그 오차들을 제곱하고 더한 값에 평균을 내는 수식이
손실함수 (loss function).
(정확하게 얘기하면 손실함수 중 mse)
즉, 이 예측모델의 총오차를 계산하는 함수이다.
이 오차를 최소화하는 방향으로 w값을 찾아라~ 라고 명령을 준다.
그게 머신러닝이다.
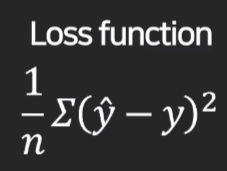
오차를 계산하는 수식은 여러가지가 있고
확률이나 분류문제에선 또 다른 오차함수를 사용할 것이다.
그리고 딥러닝 모델은 손실함수를 통해 나온 총오차값을 이용해
가중치를 다시 계산하기 때문에
손실함수를 어떤걸 쓰느냐에 따라 모델의 성능이 좌우된다.
※ 손실함수 (loss function) 종류 (feat.Chat gpt)
1. Mean Squared Error (MSE)
연속 값을 예측하는 것이 목표인 회귀 문제에 사용되는 일반적인 손실 함수입니다.
예측 값과 실제 값 사이의 평균 제곱 차이를 측정합니다.
2. Binary Cross Entropy
이 손실 함수는 출력이 0 또는 1인 이진 분류 문제에 사용됩니다.
양성 클래스의 예측 확률과 실제 확률 간의 차이를 측정합니다.
3. Categorical Cross Entropy
출력이 여러 클래스 중 하나에 속할 수 있는 다중 클래스 분류 문제에 널리 사용되는 손실 함수입니다.
예측 확률 분포와 실제 확률 분포의 차이를 측정합니다.
4. Kullback-Leibler Divergence
다중 클래스 분류 문제에 사용되는 또 다른 손실 함수입니다.
예측 확률 분포와 실제 확률 분포의 차이를 측정하지만 큰 차이에 더 중점을 둡니다.
최적의 w 찾는 법 (= 총오차가 가장 적은 w 찾는 법)
- 경사하강법 (Gradient descent)
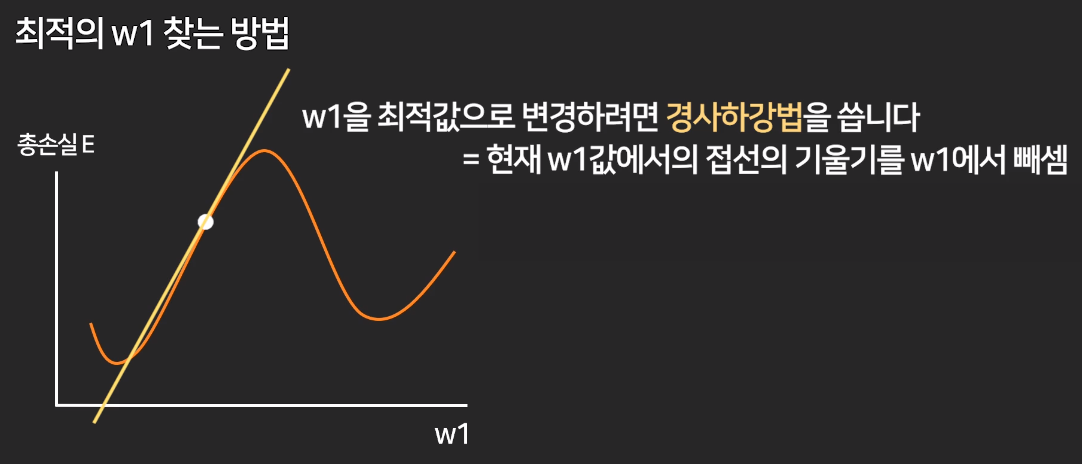

기존 w1에서 w1의 변동이 총손실 E에 얼마나 영향을 끼치는지(=기울기)를 뺀다.
경사를 타고 하강하면 결국 총손실을 최소로 만드는 w 값이 나오기 때문에.
cf. 2차원 상에서는 기울기이지만 다차원에서는 편미분.
새로운w1 = 기존w1 - (기존w1이 아주 쪼금 0.0001 변하면 총손실 E가 얼마나 크게 변하는지)

Learning rate optimizer
하지만 곡선이 여러개인데 그냥 뺄셈만 하면
local minima라고 부르는 가짜 최저점에 빠져서 더 이상 경사하강이 일어나지 않을 수 있다.
그래서
w1 = w1 - (w1이 아주 쪼금 0.0001 변하면 총손실 E가 얼마나 크게 변하는지) * learning rate
를 해야한다.
learning rate는 자유롭게 설정할 수 있는 상수이며
이걸 곱해주면 지엽적인 local minima를 뛰어넘으며 학습이 진행될 수 있다.
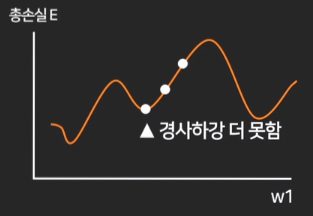
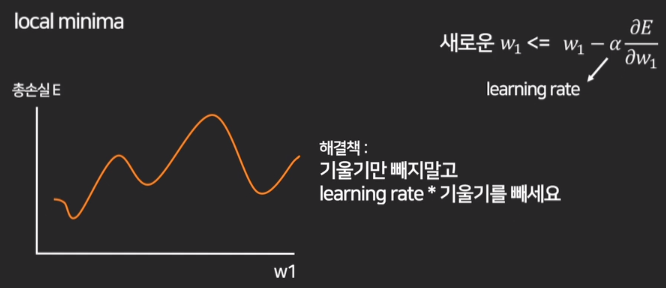

하지만 learning rate 값을 고정해두는 것도 학습 능률을 저하시킬 수 있기 때문에
이 값을 다이나믹하게 변경시키는 알고리즘이 몇개 있다.
Learning rate optimizer라고 부르는 것들.
SGD, Momentum, AdaGrad, RMSProp, Adam 등

텐서 (Tensor)
그냥 숫자, 리스트 담는 자료형이다.
왜 리스트말고 이걸 쓰냐?
행렬로 인풋 / w 값 저장이 가능해서 node 값 계산하기가 쉽기 때문에.
그리고 dimension(차원) 이 높아질수록 텐서가 다루기 편하다.
딥러닝 코드
import tensorflow as tf
# 딥러닝 모델구성
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation = 'tanh'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1, activation = 'sigmoid')
# 마지막 레이어에서 1개 결과로 압축.
# sigmoid 는 확률문제 (0 ~1 사이 확률 / 대학원 합격, 불합격)
# softmax 는 카테고리 문제
])
# 컴파일
# 확률문제 로스함수는 보통 binary_crossentropy
model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# 학습
# 리스트말고 넘파이나 텐서를 넣어야 한다.
model.fit(np.array(x), np.array(y), epochs=10)
# 예측 [영어점수, 학점, 대학등급]
예측값 = model.predict([[750, 30.7, 3], [400, 2.2, 1]])
=> 0.61 (합격확률 61%) , 0.009
# 데이터 한 행씩을 한 묶음으로 리스트화 하기
x = []
for i, rows in data.iterrows(): => 한 행씩 출력
x.append([rows['gre'], rows['gpa'], rows['rank']])
'#05.코딩애플 > +01.딥러닝' 카테고리의 다른 글
| [코딩애플] 모델 저장하기 (0) | 2023.04.24 |
|---|---|
| [코딩애플] 개 vs 고양이 이미지 분류하기 (0) | 2023.04.22 |
| [코딩애플] 개 vs 고양이 데이터 분류하기 (0) | 2023.04.19 |
| [코딩애플] CNN (0) | 2023.04.17 |

