로지스틱 회귀
회귀모델을 분류모델로 활용할 수 있다 ?!
- 이진분류 : 로지스틱 회귀 (Logistic Regression)
- 다중 클래스 분류 : 소프트맥스 회귀 (Softmax Regression)

- 선형회귀 모델이 예측한 값에 시그모이드 함수를 적용하면
0 → 0.5
-2 → 0.1~0.2
시그모이드 함수를 적용해서 0.5 보다 크면 1로 분류. 즉, 양성이다 요런것
※ 학습과 비용함수
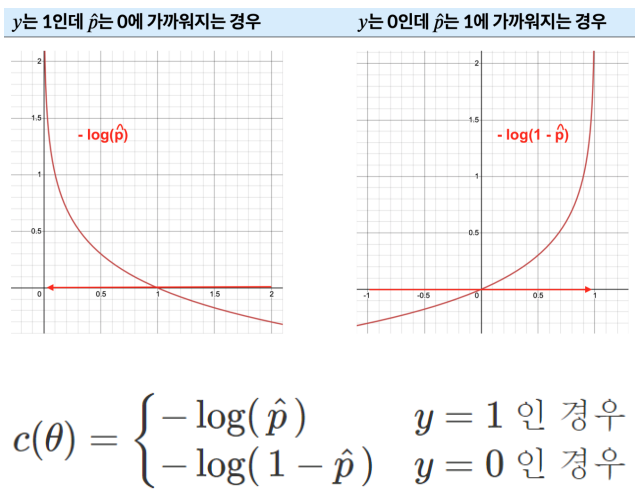
- 오른쪽 그래프
실제 0인데 1의 값에 가깝게 결과를 낼수록
아래 로그는 커지기 때문에 (=비용함수 결과값이 높아지기 때문에)
더 낮은 성능을 보인다 할수 있다.

- 로그로스함수. 정답을 더 높은 확률로 예측할수록 더 좋은 모델
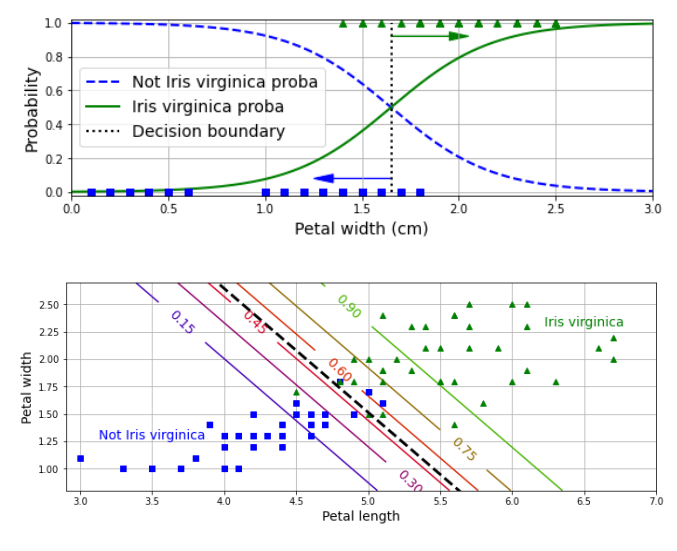
<위 그래프>
버지니카 품종인지 아닌지
녹색곡선은 버지니카 품종일 확률을 나타낼 곡선 (petal width가 클수록 높다!)
파란색은 반대
두 곡선이 만나는 지점 0.5(확률값 0.5)를 기준으로 버지니카 품종인지 아닌지 구별할 수 있게된다.
petal width가 1.65? 정도일때겠네 (결정경계)
<아래 그래프>
초록색 직선은 버지니카 품종일 가능성이 0.9인 것
검은색 점선이 0.5의 확률. 즉, 결정경계
소프트맥스 회귀 (Softmax Regression)
로지스틱 회귀모델을 일반화하여 다중 클래스 분류를 지원하도록 만든 모델

<위 이미지>
x 값을 선형회귀 모델에 넣었고 0~1사이로 변환해서 0.5 이상이 양성
<아래 이미지>
똑같이 x값을 넣어서 클래스1일 확률을 먼저 뽑는다. 0.15. 그리고 소프트맥스(클래스별 확률들의 총합이 1 이 되도록 바꿔주는 함수) 를 통과해서 최종결과가 나오게 함. 그 중 가장 높은 두번째 클래스가 이데이터에 대한 예측값이다! 라고 결정하는 것.
소프트맥스 회귀 실습
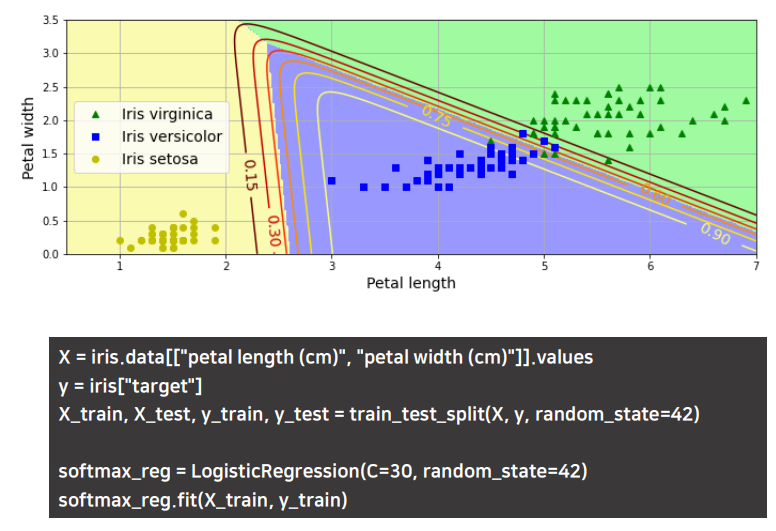
결정경계의 교점이 (클래스가 3개니까) 0.5가 아니라 33.3%가 된다.
(위 그래프에서 세가지 색의 클래스 가운데 접점에 데이터가 있다면 그 데이터는 각 클래스에 33.3%의 확률을 가지고 있다는 얘기)
곡선 자체가 네모데이터일 확률
노란색 0.9에 가까우면 0.9의 확률로 노란색
로지스틱 회귀를 통한 정오답 예측
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.linear_model import LogisticRegression
df = pd.read_csv('./datasets/초등_4학년_수학_차시문항풀이이력.csv', index_col=0)
pd.set_option('display.max_columns', len(df.columns))
df['정오답'] = df['정오답'].map({'O': 1, 'X': 0})
Q. 어떤 피쳐가 정오답에 영향을 미칠까?
df = df[['정오답', '강의타입', '동영상재생시간', '실제재생시간', '학습일', '문항코드', '대단원코드', '중단원코드', '소단원코드', '토픽코드', '난이도', '평가영역']]
df = df.dropna(subset=['정오답'])
df['학습일'] = df.학습일.apply(pd.to_datetime)
df['hour'] = df.학습일.apply(lambda x: x.hour)
카테고리형 변수 원핫인코딩
# 원핫인코딩은 카테고리형 변수에 적용가능하나 연속형 자료에는 부적합하다.
연속형에는 스케일링 추천!
df = pd.get_dummies(df, columns=['강의타입', '문항코드', '대단원코드', '중단원코드', '소단원코드', '토픽코드', '난이도', '평가영역', 'hour'])
df.head(3)
=>
df = df.drop(labels='학습일', axis=1)
X = df.iloc[:,1:].to_numpy()
Y = df['정오답'].to_numpy()
from sklearn.model_selection import train_test_split
X_train , X_test, y_train , y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
# 로지스틱 회귀를 이용하여 학습 및 예측 수행.
# solver인자값을 생성자로 입력하지 않으면 solver='lbfgs'
lr_clf = LogisticRegression() # solver='lbfgs'
lr_clf.fit(X_train, y_train)
lr_preds = lr_clf.predict(X_test)
# accuracy와 roc_auc 측정
print('accuracy: {0:.3f}, roc_auc:{1:.3f}'.format(accuracy_score(y_test, lr_preds),
roc_auc_score(y_test , lr_preds)))
=>
accuracy: 0.722
roc_auc: 0.577
더 성능을 높여보자.
재생시간 스케일링
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_scaled = scaler.fit_transform(df[['동영상재생시간','실제재생시간']])
df[['동영상재생시간','실제재생시간']] = data_scaled
df[['동영상재생시간','실제재생시간']]
=>
X = df.iloc[:,1:].to_numpy()
Y = df['정오답'].to_numpy()
from sklearn.model_selection import train_test_split
X_train , X_test, y_train , y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
# 로지스틱 회귀를 이용하여 학습 및 예측 수행.
# solver인자값을 생성자로 입력하지 않으면 solver='lbfgs'
lr_clf = LogisticRegression() # solver='lbfgs'
lr_clf.fit(X_train, y_train)
lr_preds = lr_clf.predict(X_test)
# accuracy와 roc_auc 측정
print('accuracy: {0:.3f}, roc_auc:{1:.3f}'.format(accuracy_score(y_test, lr_preds),
roc_auc_score(y_test , lr_preds)))
=>
accuracy: 0.751
roc_auc:0.643
pd.DataFrame(data=[lr_preds, y_test]) # 예측값 / 실제값
=>


'#02.천재교육 빅데이터 > +06.머신러닝 기초' 카테고리의 다른 글
| [천재교육] 군집화(Clustering) (0) | 2023.03.17 |
|---|---|
| [천재교육] 차원축소 (PCA, LDA) (0) | 2023.03.16 |
| [천재교육] 다항회귀, 학습곡선(Learning Curve) (0) | 2023.03.15 |
| [천재교육] 회귀 (Regression) (0) | 2023.03.15 |
| [천재교육] 결정트리시각화, 배깅, 랜덤포레스트 부스팅 실전 (0) | 2023.03.15 |



