비지도 학습
레이블이 없는 데이터를 학습하는 기법
군집화: 비슷한 샘플끼리의 군집을 형성하는 것이며, 아래 용도에 활용된다.
- 데이터 분석
- 고객분류
- 추천 시스템
- 검색 엔진
- 이미지 분할
- 차원 축소
- 준지도 학습
이상치 탐지: 정상 테이터와 이상치를 구분하는 데에 활용된다.
- 생산라인에서 결함제품 탐지
- 새로운 트렌드 찾기
데이터 밀도 추정: 데이터셋의 확률밀도를 추정한다.
- 이상치 분류: 밀도가 낮은 지역에 위치한 샘플
- 데이터 분석
- 데이터 시각화
군집화 (Clustering)
- Cluster : 유사한 데이터들의 모음
- Clustering : 데이터 포인트들을 별개의 군집으로 그룹화하는 것
유사성이 높은 데이터들을 동일한 그룹으로 분류하고
서로 다른 군집들이 상이성을 가지도록 그룹화 한다.
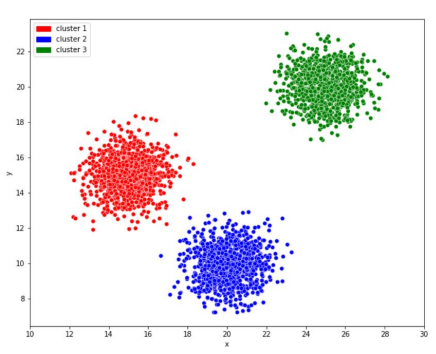
1. K-means
평균을 활용해 군집화를 함.
K 는 군집의 갯수를 의미


1-1 그래프 ==> 5개의 K를 기준으로 군집화
2-1 그래프 ==> 군집의 평균을 다시 중심점으로 할당한게 2번째 그래프
2-2 그래프 ==> 또 다시 새로운 중심점을 기준으로 군집화
3-1 그래프 ==> 중심점을 기준으로 데이터 묶고
3-2 그래프 ==> 또 다시 새로운 군집화
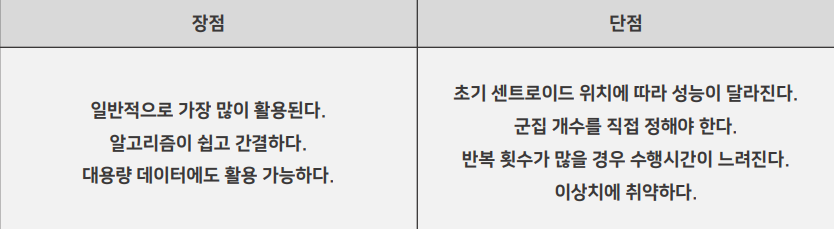
1.1. K-means++
초기의 중심점은 랜덤
두번째는 그 중심점부터 가장 멀리있는 점을 설정
세번째 또 가장 멀리 있는 중심점 설정
케이민즈의 단점을 보완할수 있다.

사이킷런의 KMeans는 ++가 기본값으로 되어있음.
* n_init ==> 케이민즈 전체 수행 몇번할래
max_iter ==> 알고리즘(군집화 → 군집평균으로 다시 중심점 잡고 → 그거 기준으로 다시 군집화) 실행 최대반복횟수
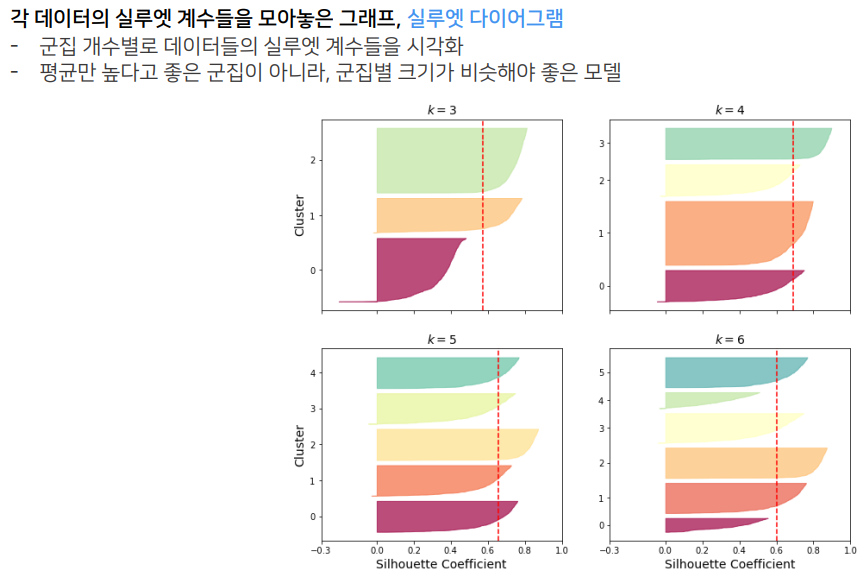
※ 실루엣 계수 (Sihouette Coefficient)
실루엣 계수는 각각의 데이터가 해당 데이터와 같은 군집 내의 데이터와는 얼마나 가깝게 군집화가 되었고,
다른 군집에 있는 데이터와는 얼마나 멀리 분포되어 있는지를 나타내는 지표입니다.
실루엣 계수가 가질 수 있는 값은 -1~1이며, 1에 가까울수록 군집화가 잘 되었음을 의미합니다.

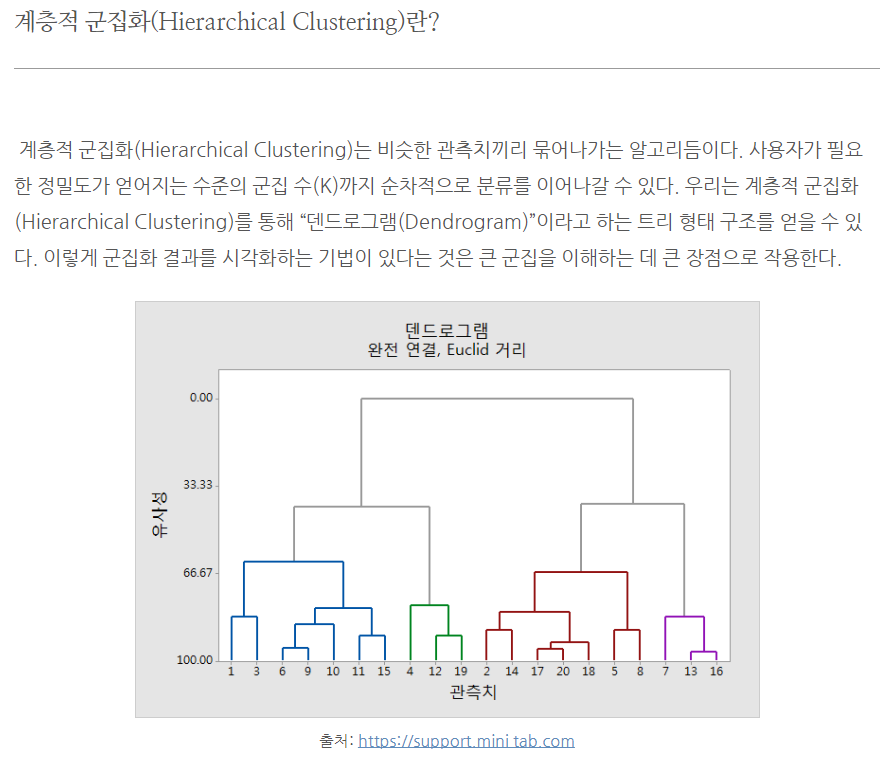
2. Hierarchical Clustering (계층적 군집분석)
데이터를 하나하나 계층에 따라 순차적으로 클러스터링 하는 기법.
클러스터의 개수를 미리 지정할 필요가 없다.


군집화는 말그대로 그룹화하는 것이고
분류는 어떤 그룹인지 예측
회귀는 어떤 값이 나올지 예측.
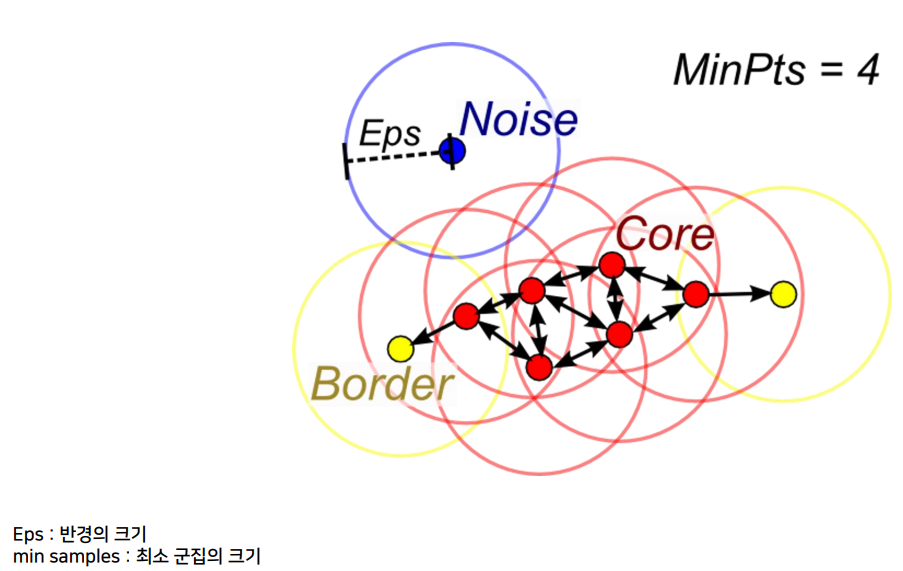
3. DBSCAN (Density-Based Spatial Clustering of applications with Noise)
DBSCAN은 "관측치 밀도가 높은 곳에는 군집이 있다. 그리고 멀리 떨어져 있는 관측치는 이상치이다" 라고 하는 기본 아이디어를 가지고 있디. 이 특징 덕분에 K-means, 계층적군집화가 가지고 있는 문제점들을 보완할 수 있다.

4. GMM (Gaussian Mixture Model, 가우시안 혼합 모델)
데이터셋이 여러 개의 혼합된 가우시안 분포를 따르는 샘플들로 구성되었다고 가정
하나의 가우시안분포가 하나의 군집이다.
* 가우시안분포: 가운데로 모여있는 그래프
보통 타원형 모양으로 군집을 이룸.


'#02.천재교육 빅데이터 > +06.머신러닝 기초' 카테고리의 다른 글
| [천재교육] 차원축소 (PCA, LDA) (0) | 2023.03.16 |
|---|---|
| [천재교육] 로지스틱 회귀, 소프트맥스 회귀 (0) | 2023.03.15 |
| [천재교육] 다항회귀, 학습곡선(Learning Curve) (0) | 2023.03.15 |
| [천재교육] 회귀 (Regression) (0) | 2023.03.15 |
| [천재교육] 결정트리시각화, 배깅, 랜덤포레스트 부스팅 실전 (0) | 2023.03.15 |



